社内の問い合わせをAIチャットボットにやらせるプロジェクトを行うことになった。
最初はChatGPT連携を謳っているクラウドサービスを契約して使っていたんだけど、精度や運用面での課題が多く、あまり活かせていない状況だった。
そこで、乗り換えを検討していたところ、AWSで割と簡単にAIチャットが構築できることが分かった。
https://catalog.workshops.aws/generative-ai-use-cases-jp/ja-JP/overview
本当に、これに書いていることをそのまんまやればAIチャットボットが作成できる。
ただし、AWSは従量課金なので要注意。利用状況にもよるが、試算すると月額15~20万円ぐらいになった。
計算方法は忘れた。
で、さらにこれは学習データを用意して読み込ませることができる(RAGチャット)。
なので、社内の各種情報を読み込ませればそれで社内用AIチャットボットが完成する。
データの読み込みはAmazon Kendraというドキュメント検索エンジンを用いる。
最初は各種ドキュメントファイルをAmazon S3にアップロードし、それをKendraに読み込ませることを想定していたのだが、以下の二点の問題点が生まれた。
- ソースとして提示されたS3のリンクをクリックしてもAccess Deniedされる。
→既に課題として管理されているが、修正待ち。。(https://github.com/aws-samples/generative-ai-use-cases-jp/issues/189) - 日々増えるナレッジを都度S3にアップロードするのが面倒。
そこで、ナレッジ共有サイト(Redmine)を直接読み込ませることにした。
KendraではWebCrawlerをデータソースに出来るので、それで行ける筈だった。
結論としては、問題なくいけた。
ただ、認証面に関してうっかりしてドツボにはまったので、同じことが起こらないようにメモを残す。
【認証情報の設定方法】
(Webcrawlerv2を用いる。基本的な部分は省略する)
- Source URLsにRedmineのサイトURLを入力する。
- AuthenticationでForm authenticationを選択する。
- AWS Secrets Manager secretでCreate and add new secretをクリックする。
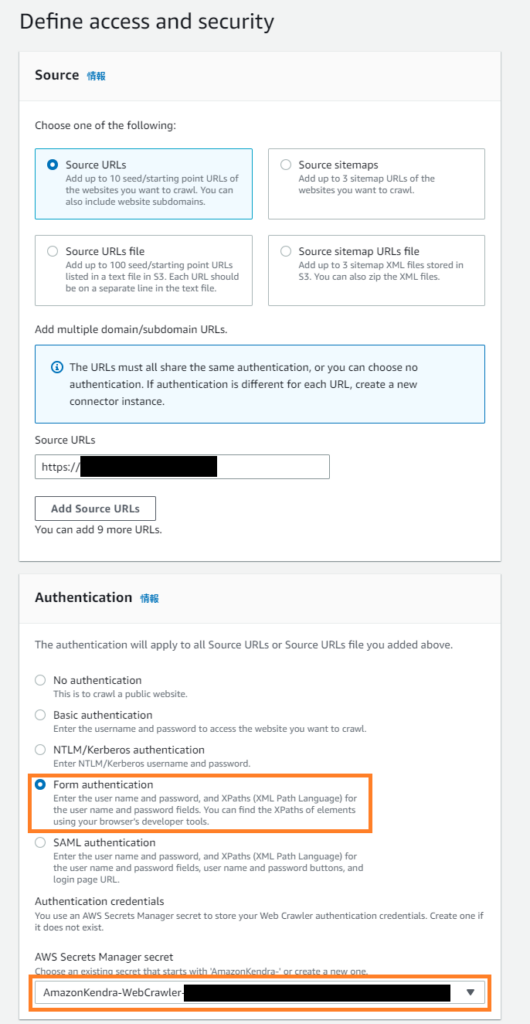
- 下記の様に各種情報を入力する。
XPathは下記サイトを参考にしてログインしたRedmineの情報を確認する。
(多分、デフォルトならこの画像と同じと思われる。)
https://dietwork.net/winactor-xpath/

- 後はダイアログに従って設定する。
恥ずかしい話なんだけど、何故かBasic認証で通そうとして悪戦苦闘してしまった。
しかも、上手くいかなかったのでRedmineのapiキーを使うという斜め下の取り組みをしてしまい、結局1日無駄にしてしまった。。。
とりあえずこれで形は出来た。
ただ、微妙に回答の的がズレていたり、回答とソースが整合しなかったりで、もう少し調整が必要そう。
どう調整するかは全く分からないので、トライアンドエラーの年末年始になりそう。